1. 서론
2. 본론
2.1. 유전자란 무엇인가?
2.2. 유전을 통한 유전정보 전달
2.3. 유전자 다양성과 질병
2.4. 인간게놈프로젝트(Human genome project: HGP)
2.5. 차세대 염기서열분석(next generation sequencing; NGS)
3. 결론
1. 서론
인간은 일생 다양한 삶을 살면서 나는 타자와 다르다고 생각하지만, 삶은 시작과 출생, 나이 듦, 그리고 질병과 죽음(生老病死)의 굴레를 벗어날 수 없다. 이러한 굴레의 생물학적 공통분모는 유전자이며, 유전자의 다양한 작용으로 출생 후 황금기를 향한 상승과 황혼기로의 하강을 거쳐 삶을 마무리하고 있다.
의학은 보편적으로 환자가 호소하는 증상이나 증후를 기반으로 진단과 치료를 시행한다. 이러한 관행은 전문가 집단의 검증을 거쳐 우리에게 친숙한 지식으로 암기, 전파되고 있다. 즉 의학은 전통적으로 증상/증후가 없으면 질병없음(0), 증상/증후가 있으면 질병있음(1)의 2분법적인 사고를 기반으로 구성되어 있지만, 우리가 알고 있듯이 세상만사는 시작과 끝 사이에 과정(process)이란 긴 단계가 있다. 즉 시작도 중요하지만, 시작이 같아도 과정이 다르면 그 결과도 달라질 수 있어 과정을 잘 조절한다면 그 예정된 운명도 바꿀 수도 있다. 유전자가 다르면 生老病死의 시작이 달라 좋은 유전자를 가진 객체가 나쁜 과정(환경)에 처해 있더라도 질병이 발생하지 않을 수도 있고, 나쁜 유전자를 가졌더라도 과정을 좋게 조절한다면 질병을 예방해 장수할 수도 있다.
생명현상의 시작과 근본 주체는 유전자다. 일반적으로 알려진 것과 같이 정자와 난자가 결합하는 수정 단계에서 유전자가 결정되는 것이 아니라, 고환이나 난소에서 정자나 난자를 만드는 과정부터 시작된다. 즉 양 부모님의 유전자(2n)가 감수분열을 통해 정자/난자의 고유한 유전자(1n)를 가지게 되며 정자/난자가 결합하는 수정 과정을 통해 인간 고유의 유전자(2n)가 만들어지게 된다. 유전자 안에는 양 부모님 혹은 인류 아니면 태초로부터 시작된 모든 생명체의 역사가 암호화된 유전정보로 기록되어 있으며 암호의 해독, 전사, 단백질 합성 과정을 통해 生老病死의 고단하고 긴 여정을 이어가고 있다.
인간의 모든 유전자를 조사함으로써 생명현상을 통째로 이해하려는 시도가 지난 세기 중반에 과학계에 제시된 이후, 오랜 과정을 거쳐 2000년도에 비로소 인간유전자지도(인간게놈프로젝트: Human genome project)의 초안이 발표되었고, 2010년도 중반에 최종본이 발표되었다. 그 후 분자생물학의 발전 특히 NGS (next generation sequencing)이라는 획기적인 방법을 통해 미국, 유럽, 일본, 중국 등에서 자국민의 유전자 염기서열 전장(full genome)과 유전자 정보를 기반으로 하여 질병 발생에 관여하는 유전자 목록을 미래의학(Future Medicine), 개별의학(Personalized Medicine), 정밀의학(Precision Medicine)이라는 이름으로 발표되고 있다.
유전자를 기반으로 한 의학은 기존 항암제 치료에 저항하는 암 변이기전을 규명하고, 변이된 암의 대사과정을 선택적으로 막을 수 있는 신약개발에도 이미 사용되고 있어 이제는 먼 미래에 다가올 신기루가 아니라 현재에도 우리의 지식과 관계없이 이미 사용되고 있다. 또한 다양한 질병 진단과, 질환 발생 기전의 이해, 새로운 치료법 개발 등으로 그 패러다임이 넓어지고 있다.
지식의 목표는 간단하게 보이지만, 지식을 얻기 위한 과정은 복잡해 부단한 노력이 필요하다. 저자는 독자들에게 1편 유전자의 전반적인 지식, 2편 유전자와 질병에 관해 기술할 예정이며, 미국 대중들이 보는 타임지나 뉴스위크지 수준으로 비교적 간단하고 쉽게 설명하고자 한다. 이를 계기로 우리 독자들이 앞으로 유전자를 기반으로 한 의학 분야에 지속적으로 관심을 가졌으면 하는 바램이다.
2. 본론
2.1. 유전자란 무엇인가?
생명체는 생식과 성장, 물질대사 등의 특징을 가지며, 이러한 특징 발현에는 유전자가 관여한다. 유전자의 물질적 특성은 단순하고도 많은 뉴클레오티드의 기계적인 연결이며, 기능적으로는 다양한 삶에 필요한 물질을 합성하는 유전정보로 구성되어 있다.
2.1.1. 물리적인 특징
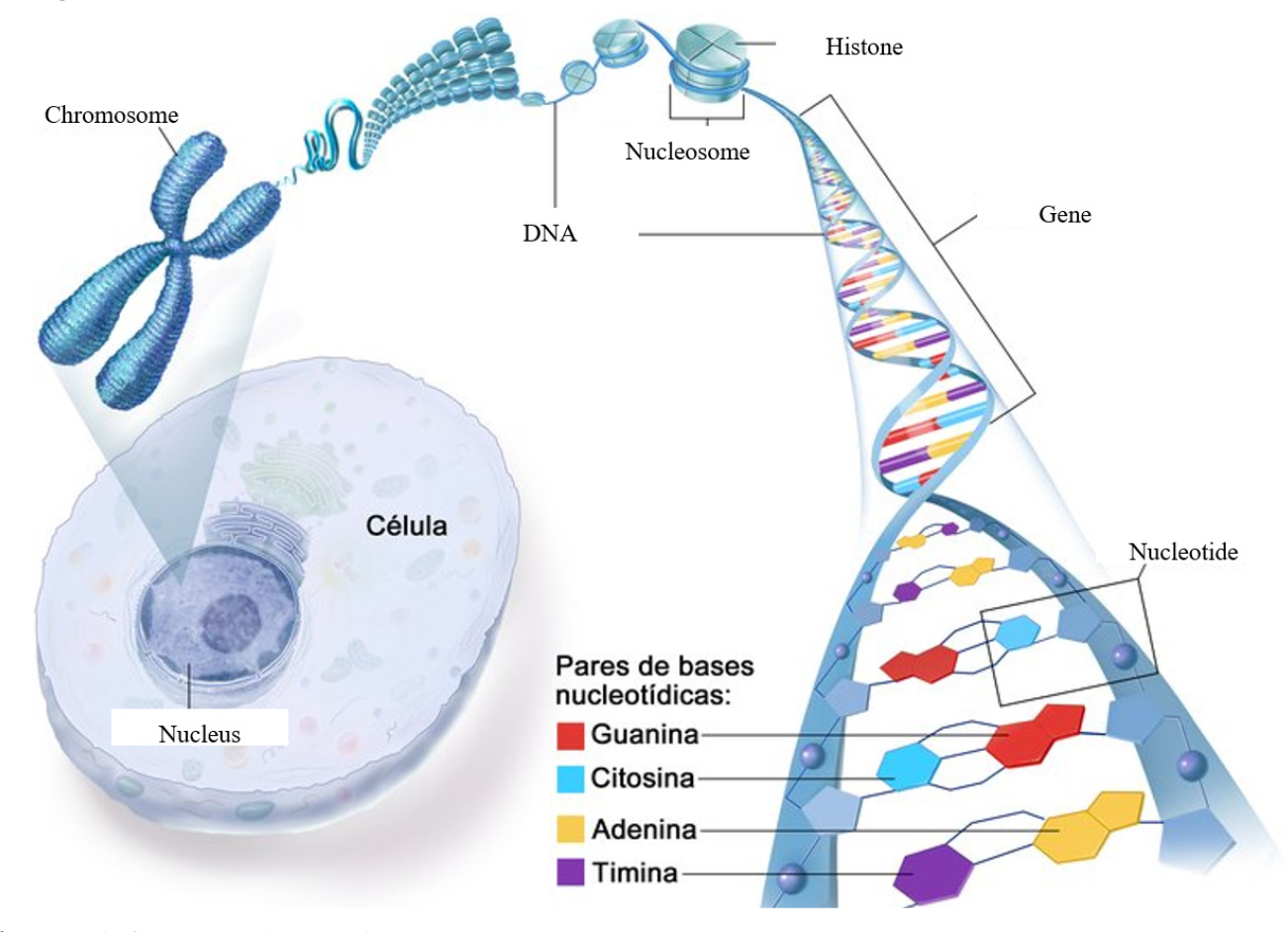
세포의 핵심 구조인 핵막 안에는 가는 실들이 뭉쳐져 있는 형태로 존재하는 염색질(chromosome)이 있는데, 이는 히스톤 단백질로 지지가 되는 nucleosome 형태로 있고 이를 다시 펼치면 다양한 뉴클레오타이드(nucleotide)의 반복으로 구성되어 있다 [그림 1]. 뉴클레오타이드는 핵산과 당, 인산으로 구성되어 있으며, 핵산은 구아닌(guanine:G), 시토신(cytosine:C), 아데닌(adenine:A), 티민(thymine:T) 중 하나로 구성되어 있다. 이때 구아닌은 시토신과 결합하고(C:G) 아데닌은 티민(A:T)과 상보적으로 결합한다. 즉 유전정보를 전담하는 기본 단위인 뉴클레오타이드의 구성은 핵산을 제외하고 당이나 인산은 같아 각 개인의 유전정보 차이는 유전자 특정 위치에 구아닌, 시토신, 아데닌, 티민 4개 중 어떤 것이 붙는가에 따라 다르다.
2.1.2. 기능적인 특징
유전자는 유전정보 전체를 복제해 세포를 증폭하거나(mitosis), 다양한 생명현상에 맞추어 DNA에서 RNA로 전사, RNA에서 단백질을 생성하기도 한다.
우리가 잘 알고 있는 PSA (prostate-specific antigen)를 통해 유전자의 기능을 이해해 보자. PSA는 단백질의 일종으로 전립선암 진단에 유용한 biomarker로 잘 알려졌지만, 인체 안에서 PSA 기능은 정액을 묽게 하는 데 있다. 성공적인 임신을 위해 사정된 정액이 여성의 질 안에서 흘러 질 외부로 유출되지 않게 하려면 질 내에서 일정한 시간 응고된 상태로 점도가 유지되어야 한다. 그러나 시간이 지나 수정을 위해 정자의 운동성을 원활하게 하려면 점도가 묽게 되어야 하는데 이 과정을 PSA가 담당하고 있다.
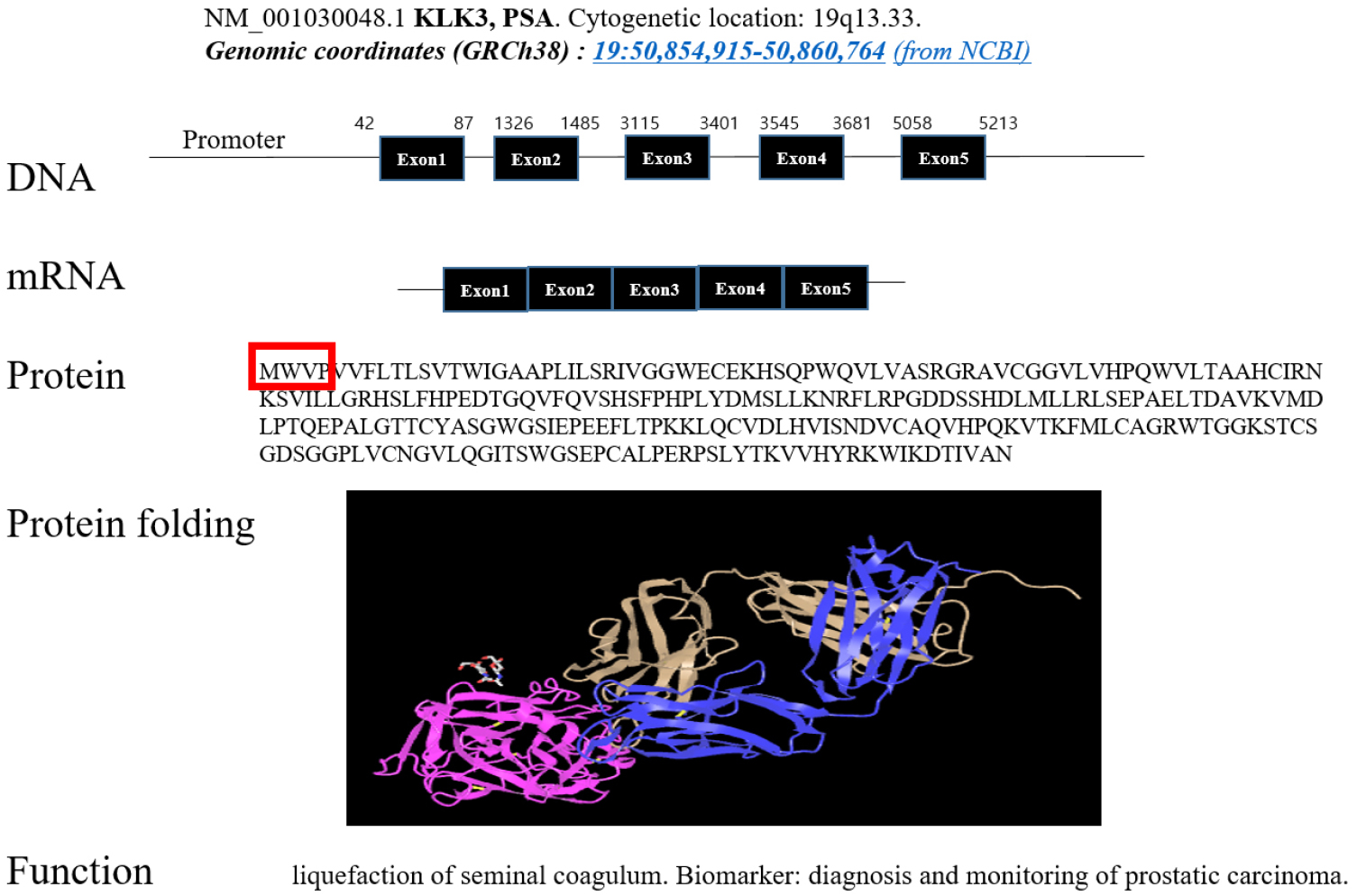
인간 PSA 유전자는 염색체 19번의 장완(long arm) 13.33에 자리 잡고 있으며, 표준 염기서열인 NM_001030048로 명명되고 있다. 성공적인 수정을 위해 단백질 합성이 필요하다면 이 유전자 부위가 있는 염색질이 열리고 전사과정을 거쳐 단백질 유전정보가 없는 intron이 제거되어 5개의 유전정보가 있는 exon 부위로만 구성된 mRNA가 핵 안에서 만들어진다. 이 mRNA가 핵막을 통과해 ribosome에 가서 mRNA에 저장된 정보를 읽고 합당한 단백질을 만든다. 3개의 핵산 정보는 1개의 코돈(codon)이 되어 특정 아미노산을 지정한다. 예를 들면 NM_001030048의 PSA유전자의 42A/43T/44G, (ATG: 메티오닌으로 코딩, M으로 표시), 45T/46G/47G, (TGG: 트립토판, W), 48G/49T/50C, (GTC; 발린, V) 등으로 코딩이 이어져 단백질 MWV---->로 합성된다 [그림 2 참조]. 지속해서 단백질을 이어 붙어 나아가다가 핵산 정보가 TGA, TAA로 조합된 코돈이 나오면 이는 합성 중지 명령으로 더는 단백질 합성이 진행되지 않고 중단된다. 만들어진 단백질은 열역학적으로 안정된 구부러진 구조로 만들어져 세포 안에서 PSA의 고유 구조로 변화하게 된다.
2.1.3. 전산학적인 분석
한 개의 세포 안에 포함된 인간 유전정보를 모두 기록한다면 이는 31억 개의 A,T,C,G의 단순한 반복으로 의미를 찾을 수는 없다. 생명현상의 숨겨진 의미를 알기 위해 반복적인 염기서열을 전산학적으로 분석하기 위해 bioinformatics란 학문이 필요하다.
예를 들어, 염기서열 –TGACTGATCCT-을 A type 00, T type 01, G type 10, C type 11로 binary coding 하다면, 위 염기서열은 전산학적으로 0110001101100001111101로 변환할 수 있다. 저자는 과거에 유닉스 환경에서 Perl 언어로 필요한 정보를 분석하였지만, 최근에는 윈도 환경에서 분석 가능한 좋은 프로그램들이 open version으로 나와 있어 능력만 있으면 쉽게 구해서 사용해볼 수 있다.
2.2. 유전을 통한 유전정보 전달
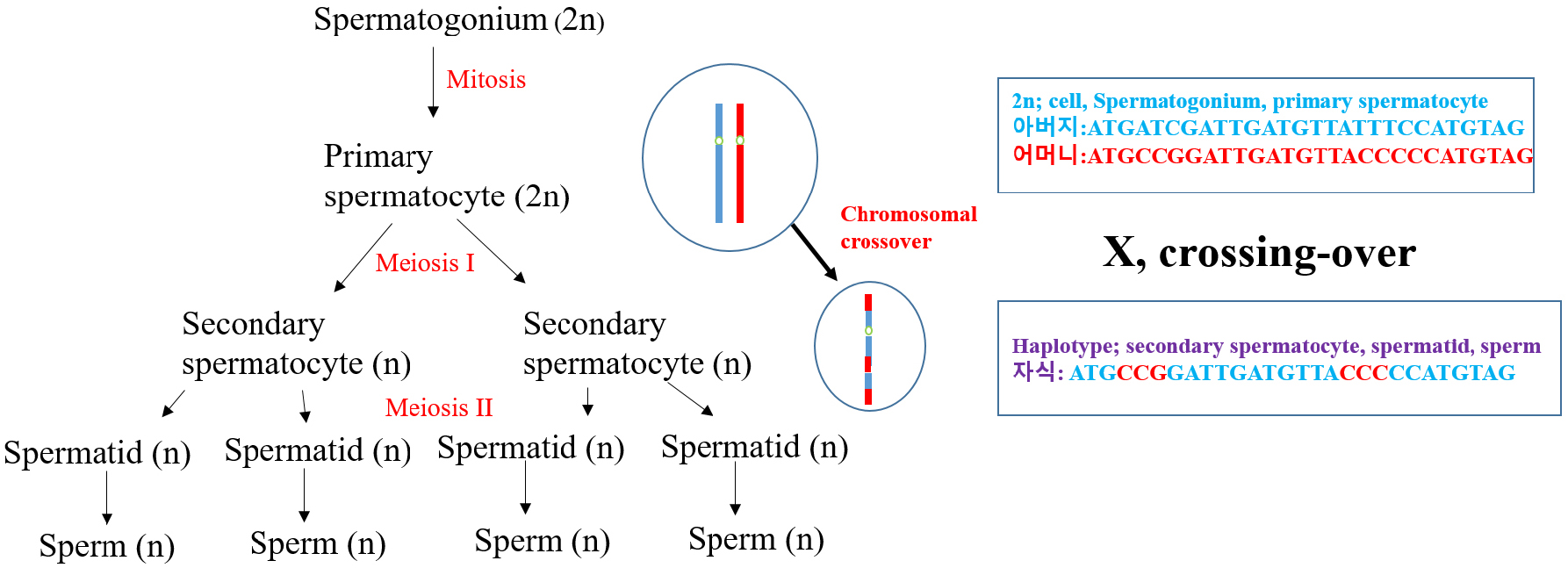
유전정보를 담당하는 염색체는 2줄로 상보적인 결합을 하고 있고 이 중 1개(1n)는 부계에서, 다른 1개(1n)는 모계에서 유래된다. 고환 세포인 spematogonium은 2n의 염색체로 구성되어 있다. 정자(primary spermatocyte; 2n)은 감수분열 과정을 통해 부계의 염색체와 모계의 염색체가 서로 교차 되어(cross-over), 2차 spermatocyte가 만들어지는데 이때 핵산 정보는 1n으로 부계나 모계와 비슷하지만, 일치하지 않는 유전정보를 가진 정자가 만들어진다. 즉 생로병사에 관여하는 자신의 유전자 결정은 일차적으로 1차 감수분열 때 결정되며 난자도 유사한 경로를 거친다. 따라서 수정을 거쳐 태어난 아이는 부모를 닮았지만, 별개의 유일무이한 유전정보를 가진 객체로 태어난다 [그림 3].
2.3. 유전자 다양성과 질병
감수분열과 수정을 거치면서 각 개인의 유전자 염기서열은 다양해지면서 진화론적으로 좋은 결과와 나쁜 결과를 잉태하게 된다. 의학적으로 좋은 결과란 생명의 연장이나 질병 없음을 의미하고 나쁜 결과는 질병과 조기 사망 등과 관련 있는 유전자 변이를 가진 것을 의미할 것이다, 유전자 다양성의 기전이나 형태 또한 매우 다양해 제한된 지면에 다 설명할 수는 없지만, 간략하게 유전자 삽입, 제거, SNP (single nucleotide polymorphism)에 관해 살펴보겠다.
2.3.1. 유전자 삽입
유전자가 단백질 코딩과 관련이 없는 intron 부위에 삽입된다면 질병 발생과 큰 상관관계는 없을 수도 있지만, 단백질 합성에 관여하는 exon 부위에 삽입되면 단백질 합성에 변화를 주어 질병 발생 가능성이 크다. 예를 들면, 4p16.3에 있는 HTT 유전자(Huntington gene)의 CAG (trinucleotide)의 반복삽입은 Huntington’s 질환 발생과 관계있는데 CAG는 glutamine 합성을 지시하는 유전 명령으로 뇌 안에 glutamine을 많이 포함된 변형된 HTT 단백질이 축적된다. 비슷한 예로 X-염색체에 존재하는 androgen receptor의 CAG 반복은 남성호르몬의 분비량과 관련이 있으며, 전립선암 발생이나 진행에 영향을 준다는 보고도 있다.
2.3.2. 유전자 결손
일부 유전자의 결손 특히 exon 부위에 결손이 발생할 수 있는데, 만일 생명현상에 중요한 역할을 하는 단백질이라면 만들어질 생명체는 모체 안에서 수정이 안 되거나 수정이 되어도 유산될 가능성이 크다. 다양한 형태의 질병이 있을 수 있겠지만, XO Turner 증후군(45,X, or 45XO)처럼 X 염색체의 전체 혹은 일부가 결손되어 발생할 수도 있다.
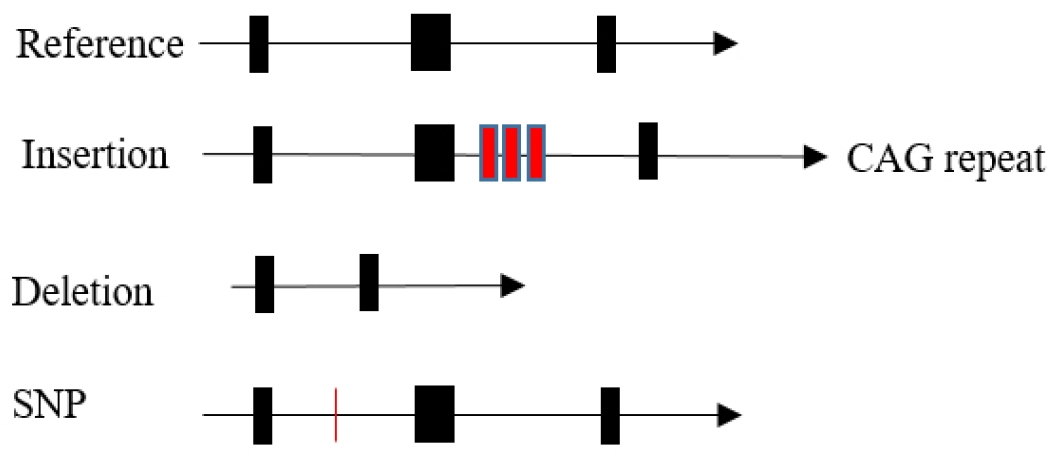
2.3.3. 단일염기다형성(single nucleotide polymorphism; SNP)
지구에는 다양한 인종이 살고 있는데, 그들 간의 유전자는 99.9%가 같고 단지 0.1%의 차이만 보여 매우 작은 염기서열의 차이로 인해 각 인종 간의 다양성이나 개인의 다양성이 나타난다. 유전자 다형성의 기원에 대해서는 여러 가설이 있겠지만, 아마도 인체 내의 정자/난자의 DNA 복제 과정 중에 발생한 작은 오류가 고쳐지지 않고 대를 이어 유전된다고 추정되고 있으며, 이러한 염기의 다형성에 의해 민족 간의 고유 질환이나 각 개인의 당뇨/ 혈압 등의 만성질환이나 암 등이 대를 이어 발생되는 것으로 생각된다. 이에 따라 최근 많은 국가에서 이를 이용한 질병 biomarker 개발에 많은 투자를 하고 있다.
염기서열 다형성 개념 안에는 단일염기(single nucleotide)의 차이로 인한 다형성(SNP)을 포함해 작은 규모의 염기 반복을 보이는 microsatellite, 작은 규모의 염기 삽입과 결손 등이 포함될 수도 있겠지만, 보편적으로는 가장 많이 관찰되는 단일염기다형성으로 정의된다. 과거에는 다형성 분석방법이 조잡하거나 부정확하고, 검사 건수가 적고, 제한된 인종에서 시행되어 인간 유전체 안에 발견된 염기서열 다형성이 적어 통상 인구집단의 1% 이상의 빈도에서 다형성이 관찰될 때 그 중요성을 인정하는 경향이 있었다. 그러나, 최근 다양한 인종을 대상으로, 그리고 NGS (next generation sequencing) 등을 이용한 깊이 있는 분석 등을 통해 과거에 확인되지 않았던 많은 SNP가 발굴되고 있으며 최근 11억 개 정도의 염기서열 다형성이 SNP 이름으로 발굴 보고되고 있다.
SNP는 유전자 영역 어디에서 관찰되는가에 따라 rSNP (regulatory SNP: 전사 조절인자 영역에 존재해 mRNA 발현에 영향을 준다), iSNP (intron SNP로 단백질 합성에 중요한 역할을 하지 않지만, mRNA의 형태 유지나 다른 유전자나 단백질 결합 등에 영향을 줄 수 있다), cSNP (coding SNP로 단백질 코딩에 관여해 아미노산 변이를 유발해 단백질 기능에 큰 영향을 주어 질병 발생 등에 직접적인 영향을 줄 수 있다), 마지막으로 sSNP (synonymous SNP로 위치는 단백질 코딩영역의 DNA 변화는 있지만, 아미노산 변화에는 영향을 미치지 않는다)로 구분된다.
예를 들면 과거 저자가 연구한 rs266882라 명명되는 SNP가 있다, 이는 PSA 전사 부위에 있는 rSNP의 일종으로 G형과 A형이 있다. PSA 유전자 다형성은 민족 간의 PSA 측정치의 차이를 발생시킬 수 있는데, 이 차이는 인종 간에 전립선암 진단 과정에서 일부 차이를 나타낼 수 있다(Lee, et al. Biochemical genetics 2013; 51(3-4):264-74). 따라서 SNP는 현재 당뇨병, 고혈압 등 만성병이나 암 발생 등의 원인으로 지목되고 있어 많은 나라의 전문가들이 이미 개발된 SNP를 대상으로 case-control study를 시행하고 있다. 그 임상적 의미는 이어지는 2편에 자세하게 다룰 예정이다.
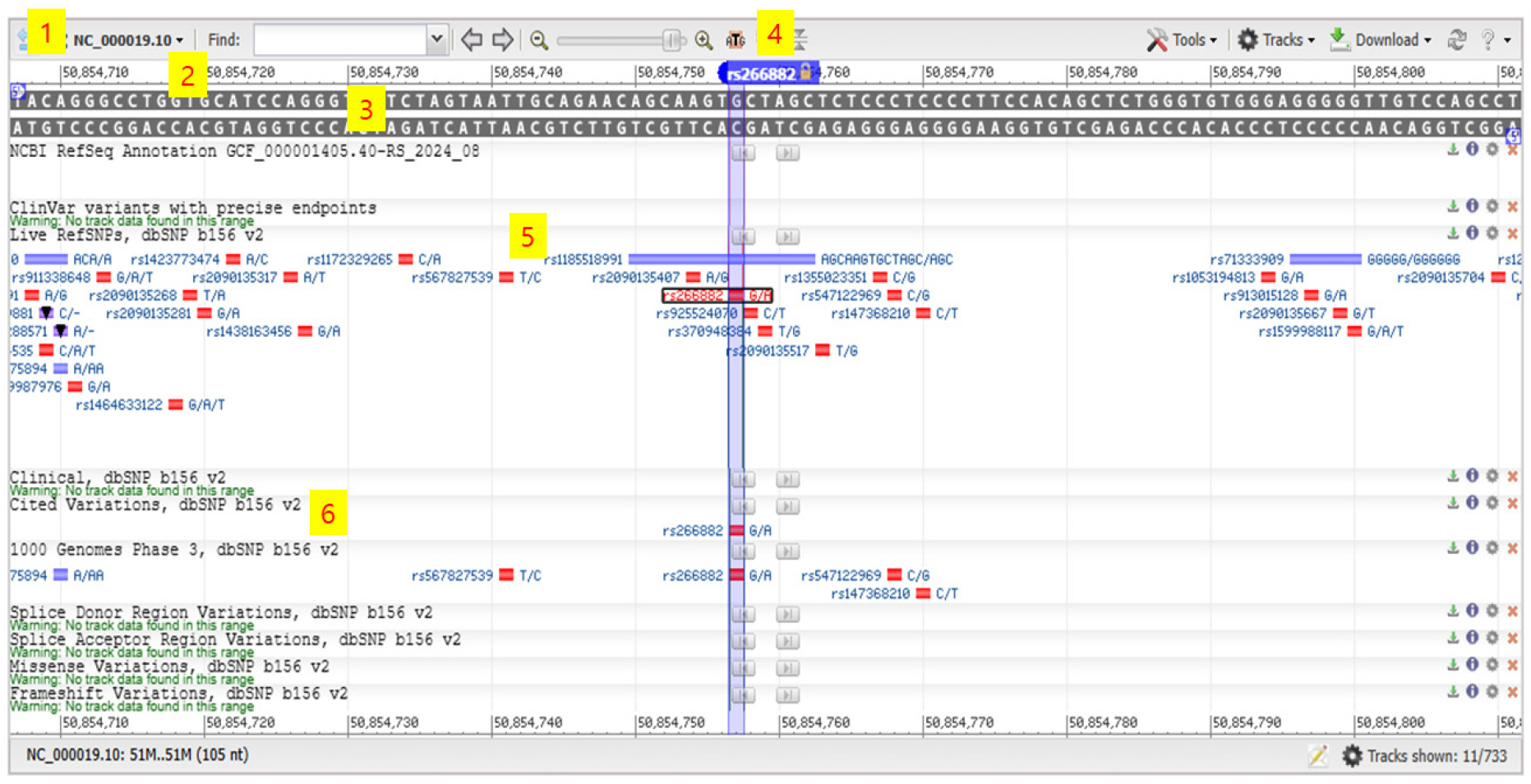
1, NC_000019.1 (Homo sapiens 염색체 19번 표준 염기서열), 2. 인간 19번 염색체 안에 위치 정보. 즉 SNP rs266882는 19번 염색체의 50854757번에 자리 잡고 있음을 알 수 있다. 3. 19번 염색체 안에 부계 DNA 염기서열과 모계 염기서열이 상보적으로 결합하여 있다. 4. SNP rs266882은 G type (C type)과 A type (T type)이 있다. 5. rs266882 주위에 무수한 다른 SNP들이 관찰됨. 6. 수많은 SNP에 대해 그 임상적인 의미를 분석한 기록. 여기에 기록된 1000 유전체 프로젝트(1000 Genomes Project)는 2008년 1월에 영국, 미국, 중국이 합작하여 3년 이내에 다양한 인종으로 구성된 인간 1000명의 유전체를 해독하는 국제 프로젝트이다. 인간게놈프로젝트 이후 가장 큰 규모의 유전체 프로젝트였으며, 기존에 한두 명의 게놈 지도를 해석하는 것이 아니라, 빠른 속도로 많은 사람의 유전체를 한꺼번에 해석하여 변이체학의 기초를 이룰 수 있는 매우 귀중한 자료를 만드는 것이 목적이었다. 또한, 이 자료는 일반인이 쉽게 찾고 정보를 얻을 수 있게 공개되었다.
2.4. 인간게놈프로젝트(Human genome project: HGP)
인간게놈프로젝트는 인간 염색체 안에 든 31억 개의 모든 염기쌍의 서열을 밝혀 인간 유전자 연구의 기준점을 마련할 목적으로 시행된 국제협력사업이다. 먼저 실험적으로 질병의 원인이 되는 유전자 위치를 추정하고 Bioinformatics tool을 이용해 분석된 유전자의 기능 추정 등을 시행해 인간유전체 연구의 토대를 마련하였다. 이후에는 NGS 등을 통한 염기서열 분석에 표준 염기서열로 사용되고 있는데, 현재에는 이 기준을 가지고 NGS를 통해 얻은 수많은 자료를 응용해 개인, 인종 간의 유전자 차이를 조사하여, 인류의 역사, 이동, 질병 발생 등을 분석하고 있으며, 질병의 진단, 치료, 발생억제 및 신약 개발 등에도 사용되고 있다.
방법에 대해서 간략하게 언급하고자 한다. 유전자 분석에 사용하는 검체는 백혈구 덩어리로 뭉쳐져 있어 쉽게 분석할 수 없다 (6-1). HGP에 사용되었던 shotgun 방식은 백혈구 덩이 즉 DNA 덩이를 잘게 절단해 크기가 다른 수많은 절편(절편 1개당 평균 200,000개의 유전정보 포함함)으로 나눈 후 (6-2) 이를 sequencing vector (BAC; bacterial artificial chromosome)에 결합해 분석 가능한 크기로 나눈다 (6-3). Vector에 포함된 염기서열을 이용해 기존 염기서열 분석방법(Sanger sequencing)으로 결합된 미지의 염기서열을 읽는다 (6-4), Bioinformatics을 이용해 부분적으로 공유하는 염기서열을 확인한 후 (6-5), 이를 이어 붙여 좀 더 큰 염기서열을 만들고 (6-6), 이 과정을 반복해 HGP를 완성한다.

2.5. 차세대 염기서열분석(next generation sequencing; NGS)
Shotgun 방법을 이용한 HGP는 15년이 걸렸고 연구 경비 또한 30억 달러가 지출되어 결과 도출에 걸리는 시간이 길었고, 대규모 환자를 대상으로 연구하기에는 많은 단점이 있었다. 이를 보완하기 위해 NGS 방법이 개발되었으며 이후 수많은 간편화 작업을 통해 1개 검체 당 분석비용이 600달러로 저렴해졌으며, 실험도 자동화되어 수일 내 결과를 도출하고 분석을 받아볼 수 있게 되었다.
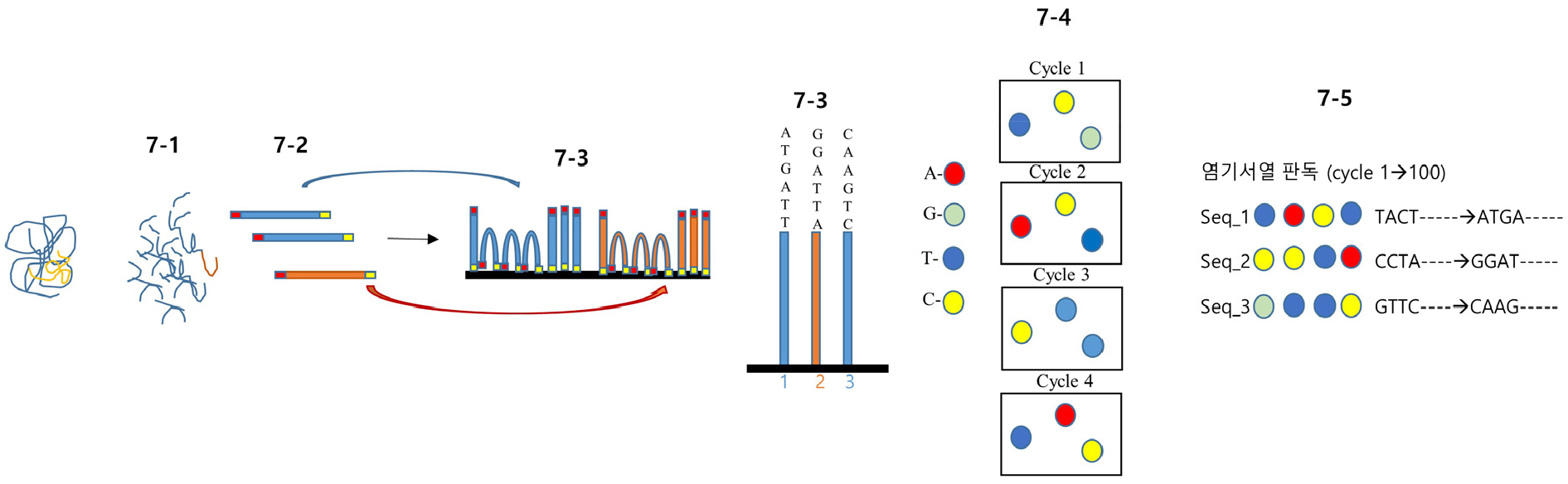
NGS의 방법상 가장 큰 특징은 다음과 같다. Shotgun 방법과 유사하게, 뭉쳐져 있는 염색체를 일정한 크기의 염기서열로 분쇄한 후 (7-1) 분쇄된 서열에 bar-code와 adaptor 등을 삽입하여 자동화 분석을 통한 추적이 가능하게 한 후 (7-2) 이를 유리기판에 붙인다. 유리기판에서 유전자 증폭을 시킨 후 증폭 산물을 유리판에 세운다 (7-3). 핵산 4개에 특이한 형광물질 4개를 붙인 후 이를 유리기판에 붙은 염기서열에 교잡시킨다. 붙지 않는 형광물질은 제거한 후 염기서열에 상보적으로 결합한 형광물질에 특이하게 반응하는 4파장의 광선을 노출한 후 이를 영상분석장치로 사진을 찍어 컴퓨터가 스스로 유리기판 각 위치에 존재하는 특이한 염기서열을 확인하고 bar-code 정보와 특이 파장에 감광된 핵산 정보 즉 A, T, G, C 정보를 저장한다 (7-4) 그 후 특정 증폭 cycle에 붙은 형광물질과 염기서열을 제거한다, 다음 노출되는 염기서열 역시 같은 방법으로 사진을 찍은 후 이를 약 100회 반복한다(parallel sequencing).
결과적으로 유리판에 붙은 수많은 증폭된 산물인 염기서열을 대상으로 얻은 각 증폭 산물에는 100개의 염기서열이 있고 (7-5) 이를 Bioinformatics tool을 이용해 기준 염색체 위치(HGP에서 얻은 표준 염기서열)에 배열해 각각 표준 염색체 안으로 그 위치를 결정한다(수학적으로 100개의 핵산 정보가 무작위로 결합하여 특정한 100개의 염기로 구성된 1개의 특정 염기서열을 우연히 만들 확률은 0.25100 으로 이는 HGP의 표준 염기서열에서 중복으로 발견될 확률은 0에 수렴한다고 할 수 있다). 따라서 증폭된 염기서열은 어떤 유전자에서 온 것인가를 쉽게 알 수 있고 이 유전자의 다형성 또한 알 수 있다, NGS의 장점은 빠르고 비용이 절감되며 1% 미만에서 발견되는 비교적 드문 염기서열도 확인할 수 있어 최근 광범위하게 사용되고 있다.